 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral City
Papers and Code
CWSSNet: Hyperspectral Image Classification Enhanced by Wavelet Domain Convolution
Sep 11, 2025Hyperspectral remote sensing technology has significant application value in fields such as forestry ecology and precision agriculture, while also putting forward higher requirements for fine ground object classification. However, although hyperspectral images are rich in spectral information and can improve recognition accuracy, they tend to cause prominent feature redundancy due to their numerous bands, high dimensionality, and spectral mixing characteristics. To address this, this study used hyperspectral images from the ZY1F satellite as a data source and selected Yugan County, Shangrao City, Jiangxi Province as the research area to perform ground object classification research. A classification framework named CWSSNet was proposed, which integrates 3D spectral-spatial features and wavelet convolution. This framework integrates multimodal information us-ing a multiscale convolutional attention module and breaks through the classification performance bottleneck of traditional methods by introducing multi-band decomposition and convolution operations in the wavelet domain. The experiments showed that CWSSNet achieved 74.50\%, 82.73\%, and 84.94\% in mean Intersection over Union (mIoU), mean Accuracy (mAcc), and mean F1-score (mF1) respectively in Yugan County. It also obtained the highest Intersection over Union (IoU) in the classifica-tion of water bodies, vegetation, and bare land, demonstrating good robustness. Additionally, when the training set proportion was 70\%, the increase in training time was limited, and the classification effect was close to the optimal level, indicating that the model maintains reliable performance under small-sample training conditions.
Hyperspectral Imaging-Based Perception in Autonomous Driving Scenarios: Benchmarking Baseline Semantic Segmentation Models
Oct 29, 2024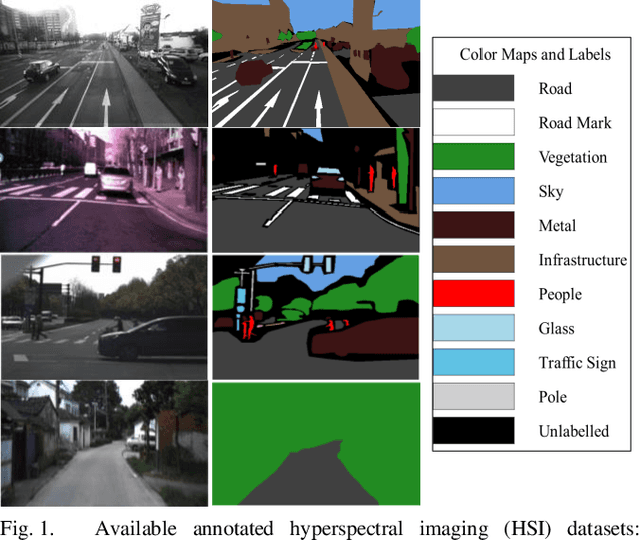

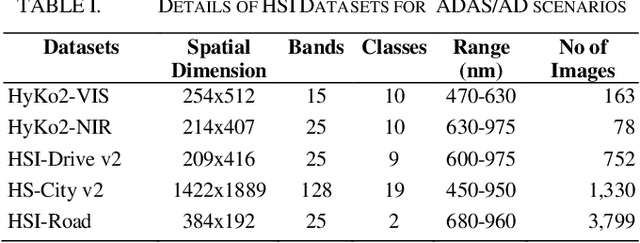
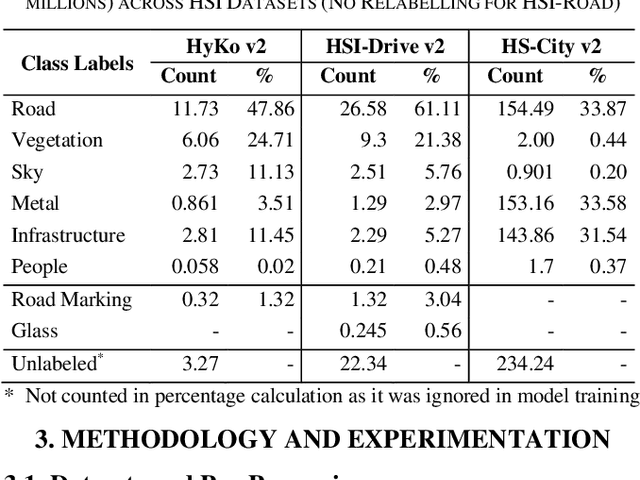
Hyperspectral Imaging (HSI) is known for its advantages over traditional RGB imaging in remote sensing, agriculture, and medicine. Recently, it has gained attention for enhancing Advanced Driving Assistance Systems (ADAS) perception. Several HSI datasets such as HyKo, HSI-Drive, HSI-Road, and Hyperspectral City have been made available. However, a comprehensive evaluation of semantic segmentation models (SSM) using these datasets is lacking. To address this gap, we evaluated the available annotated HSI datasets on four deep learning-based baseline SSMs: DeepLab v3+, HRNet, PSPNet, and U-Net, along with its two variants: Coordinate Attention (UNet-CA) and Convolutional Block-Attention Module (UNet-CBAM). The original model architectures were adapted to handle the varying spatial and spectral dimensions of the datasets. These baseline SSMs were trained using a class-weighted loss function for individual HSI datasets and evaluated using mean-based metrics such as intersection over union (IoU), recall, precision, F1 score, specificity, and accuracy. Our results indicate that UNet-CBAM, which extracts channel-wise features, outperforms other SSMs and shows potential to leverage spectral information for enhanced semantic segmentation. This study establishes a baseline SSM benchmark on available annotated datasets for future evaluation of HSI-based ADAS perception. However, limitations of current HSI datasets, such as limited dataset size, high class imbalance, and lack of fine-grained annotations, remain significant constraints for developing robust SSMs for ADAS applications.
Cross-City Matters: A Multimodal Remote Sensing Benchmark Dataset for Cross-City Semantic Segmentation using High-Resolution Domain Adaptation Networks
Oct 03, 2023



Artificial intelligence (AI) approaches nowadays have gained remarkable success in single-modality-dominated remote sensing (RS) applications, especially with an emphasis on individual urban environments (e.g., single cities or regions). Yet these AI models tend to meet the performance bottleneck in the case studies across cities or regions, due to the lack of diverse RS information and cutting-edge solutions with high generalization ability. To this end, we build a new set of multimodal remote sensing benchmark datasets (including hyperspectral, multispectral, SAR) for the study purpose of the cross-city semantic segmentation task (called C2Seg dataset), which consists of two cross-city scenes, i.e., Berlin-Augsburg (in Germany) and Beijing-Wuhan (in China). Beyond the single city, we propose a high-resolution domain adaptation network, HighDAN for short, to promote the AI model's generalization ability from the multi-city environments. HighDAN is capable of retaining the spatially topological structure of the studied urban scene well in a parallel high-to-low resolution fusion fashion but also closing the gap derived from enormous differences of RS image representations between different cities by means of adversarial learning. In addition, the Dice loss is considered in HighDAN to alleviate the class imbalance issue caused by factors across cities. Extensive experiments conducted on the C2Seg dataset show the superiority of our HighDAN in terms of segmentation performance and generalization ability, compared to state-of-the-art competitors. The C2Seg dataset and the semantic segmentation toolbox (involving the proposed HighDAN) will be available publicly at https://github.com/danfenghong.
BiGSeT: Binary Mask-Guided Separation Training for DNN-based Hyperspectral Anomaly Detection
Jul 14, 2023



Hyperspectral anomaly detection (HAD) aims to recognize a minority of anomalies that are spectrally different from their surrounding background without prior knowledge. Deep neural networks (DNNs), including autoencoders (AEs), convolutional neural networks (CNNs) and vision transformers (ViTs), have shown remarkable performance in this field due to their powerful ability to model the complicated background. However, for reconstruction tasks, DNNs tend to incorporate both background and anomalies into the estimated background, which is referred to as the identical mapping problem (IMP) and leads to significantly decreased performance. To address this limitation, we propose a model-independent binary mask-guided separation training strategy for DNNs, named BiGSeT. Our method introduces a separation training loss based on a latent binary mask to separately constrain the background and anomalies in the estimated image. The background is preserved, while the potential anomalies are suppressed by using an efficient second-order Laplacian of Gaussian (LoG) operator, generating a pure background estimate. In order to maintain separability during training, we periodically update the mask using a robust proportion threshold estimated before the training. In our experiments, We adopt a vanilla AE as the network to validate our training strategy on several real-world datasets. Our results show superior performance compared to some state-of-the-art methods. Specifically, we achieved a 90.67% AUC score on the HyMap Cooke City dataset. Additionally, we applied our training strategy to other deep network structures, achieving improved detection performance compared to their original versions, demonstrating its effective transferability. The code of our method will be available at https://github.com/enter-i-username/BiGSeT.
Hyperspectral City V1.0 Dataset and Benchmark
Aug 13, 2019



This document introduces the background and the usage of the Hyperspectral City Dataset and the benchmark. The documentation first starts with the background and motivation of the dataset. Follow it, we briefly describe the method of collecting the dataset and the processing method from raw dataset to the final release dataset, specifically, the version 1.0. We also provide the detailed usage of the dataset and the evaluation metric for submitted the result for the 2019 Hyperspectral City Challenge.
Hyperspectral Image Semantic Segmentation in Cityscapes
Dec 18, 2020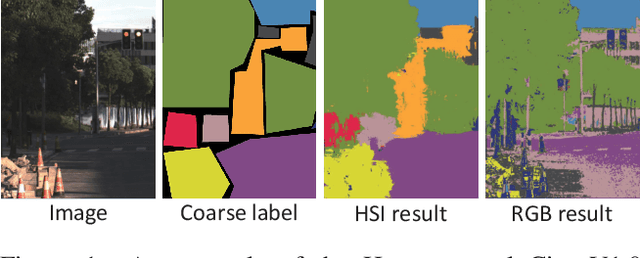



High-resolution hyperspectral images (HSIs) contain the response of each pixel in different spectral bands, which can be used to effectively distinguish various objects in complex scenes. While HSI cameras have become low cost, algorithms based on it has not been well exploited. In this paper, we focus on a novel topic, semi-supervised semantic segmentation in cityscapes using HSIs.It is based on the idea that high-resolution HSIs in city scenes contain rich spectral information, which can be easily associated to semantics without manual labeling. Therefore, it enables low cost, highly reliable semantic segmentation in complex scenes.Specifically, in this paper, we introduce a semi-supervised HSI semantic segmentation network, which utilizes spectral information to improve the coarse labels to a finer degree.The experimental results show that our method can obtain highly competitive labels and even have higher edge fineness than artificial fine labels in some classes. At the same time, the results also show that the optimized labels can effectively improve the effect of semantic segmentation. The combination of HSIs and semantic segmentation proves that HSIs have great potential in high-level visual tasks.
From Google Maps to a Fine-Grained Catalog of Street trees
Oct 07, 2019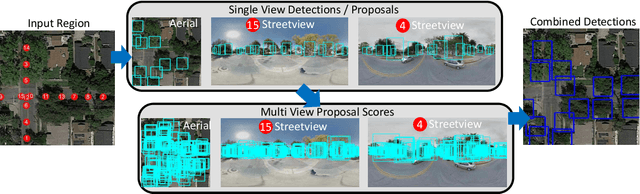
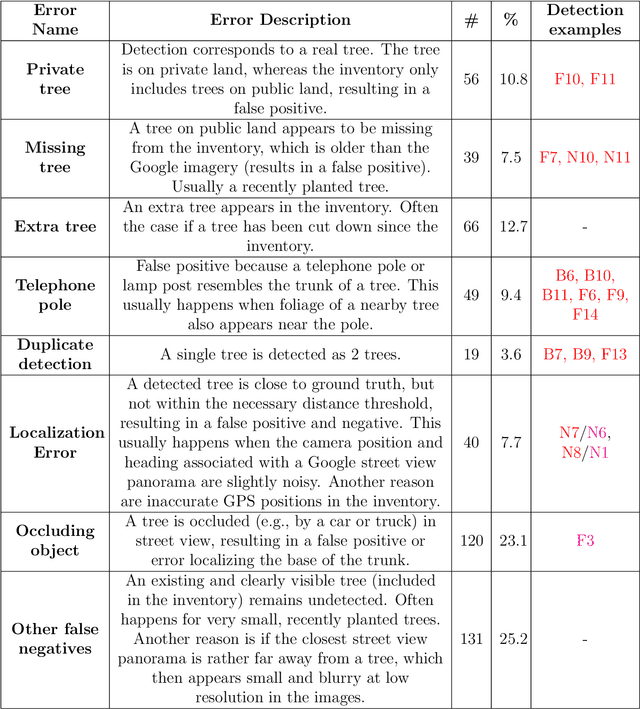

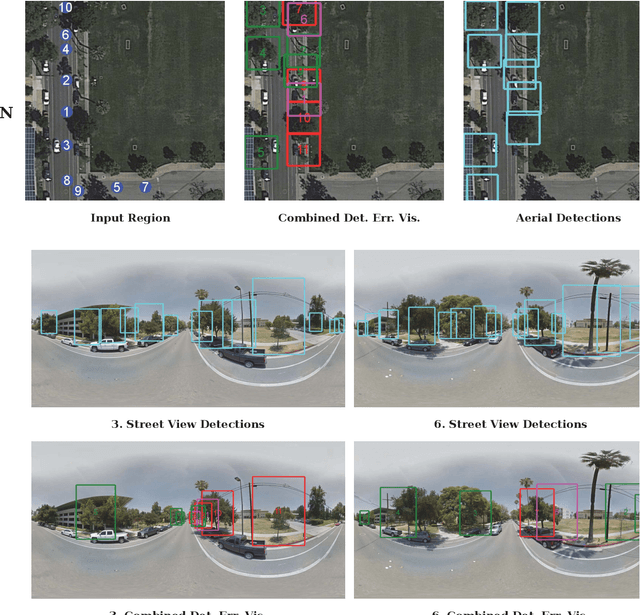
Up-to-date catalogs of the urban tree population are important for municipalities to monitor and improve quality of life in cities. Despite much research on automation of tree mapping, mainly relying on dedicated airborne LiDAR or hyperspectral campaigns, trees are still mostly mapped manually in practice. We present a fully automated tree detection and species recognition pipeline to process thousands of trees within a few hours using publicly available aerial and street view images of Google MapsTM. These data provide rich information (viewpoints, scales) from global tree shapes to bark textures. Our work-flow is built around a supervised classification that automatically learns the most discriminative features from thousands of trees and corresponding, public tree inventory data. In addition, we introduce a change tracker to keep urban tree inventories up-to-date. Changes of individual trees are recognized at city-scale by comparing street-level images of the same tree location at two different times. Drawing on recent advances in computer vision and machine learning, we apply convolutional neural networks (CNN) for all classification tasks. We propose the following pipeline: download all available panoramas and overhead images of an area of interest, detect trees per image and combine multi-view detections in a probabilistic framework, adding prior knowledge; recognize fine-grained species of detected trees. In a later, separate module, track trees over time and identify the type of change. We believe this is the first work to exploit publicly available image data for fine-grained tree mapping at city-scale, respectively over many thousands of trees. Experiments in the city of Pasadena, California, USA show that we can detect > 70% of the street trees, assign correct species to > 80% for 40 different species, and correctly detect and classify changes in > 90% of the cases.